# Function to implement Sieve of Eratosthenes
sieve <- function(n) {
# Create a boolean array "prime[0..n]" and
# initialize all entries it as true.
# A value in prime[i] will finally be
# false if i is Not a prime, else true.
prime <- rep(TRUE, n + 1)
# Set entries for 0 and 1 to false as
# they are not prime numbers
prime[1] <- FALSE
prime[2] <- TRUE
# Loop through the array and set the
# value of each element to false if
# it is not a prime number.
for (p in 2:n) {
if (prime[p]) {
# Update all multiples of p
for (i in 2 * p:n) {
prime[i] <- FALSE
}
}
}
# Return a vector of prime numbers
return(which(prime))
}ChatGPT fail: Sieve of Eratosthenes
AI
R
ChatGPT
data science
ChatGPT writes buggy R in a quick test
My flirtation with ChatGPT continues.
A few days ago I had some fun asking it to compose emotive sonnets about data science. That was entertaining, and I maintain that anyone who isn’t recognizing this moment as a major inflection point for authoring content of any kind isn’t paying attention. And yes, this extends to writing code. Some people are (rightly) fearful that AI will be able to write better code than humans very soon, for approximately a nothingth of the cost, and that we might actually be there now. Stackoverflow has temporarily banned ChatGPT, though how they’re going to police that remains a bit of a mystery to me.
There may be some divine symmetry to AI systems obsoleting the human programmers that spawned them, but I don’t think we’re quite there yet. I asked ChatGPT to implement a Sieve of Eratosthenes in R, and this was its confident response:
Pretty impressive. Concise, clean, and commented (well, with a caps typo), with a paragraph of explanatory text below it describing how it works, it initially put a chill down my spine.
Until a few seconds later, when I noticed some obvious issues:
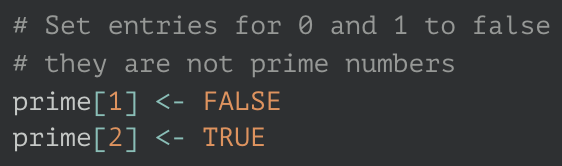
# Set entries for 0 and 1 to false as
# they are not prime numbers
prime[1] <- FALSE
prime[2] <- TRUEThere are at least 2 bugs here. The first is that R vectors are one-based, not zero-based, and the code uses the numbers being tested as primes as the index for the vector; the code is actually OK, but the comment is wrong. The second is even with the off-by-one index, the code doesn’t do what the comment describes (set two values to false). Also, the second line is redundant because the entire vector has already been initialized to TRUE. And finally, of course, when run, this code produces incorrect output:
> sieve(100)
[1] 2 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45
[24] 47 49 51 53 55 57 59 61 63 65 67 69 71 73 75 77 79 81 83 85 87 89 91
[47] 93 95 97 99 101Starts off OK, but then 9 appears, and it goes downhill rapidly after that.
It’s easy enough to fix:
- start the array with
FALSEfor 1, since 1 is not prime (logic error) - use the rounded square root of
nfor the upper boundary, notn(logic error) - use a
seqfunction iterating byp, starting atp^2, to mark the composites; the R codefor (i in 2 * p:n)doesn’t do that (language error).
sieve <- function(n) {
# Create a boolean array "prime[1..n]" and
# initialize all entries it as true, except
# for prime[1] = FALSE.
# A value in prime[i] will finally be
# false if i is not a prime, else true.
# 1 is not a prime number; initialize it to FALSE.
prime <- c(FALSE, rep(TRUE, n - 1))
# Loop through the array and set the
# value of each element to false if
# it is not a prime number.
for (p in 2:floor(sqrt(n))) {
if (prime[p]) {
# Update all multiples of p not exceeding n, starting at p^2
for (i in seq(p ^ 2, n, by = p)) {
prime[i] <- FALSE
}
}
}
# Return a vector of prime numbers
return(which(prime))
}The point of this isn’t to flex on first-year computer-science R; the point is that the code is presented authoritatively by the AI (even with their general disclaimers that things may be wrong), and since a lot of what passes for programming these days seems to be blindly copying and pasting code fragments from Stackoverflow, this is another vector where that could happen.
So: it’s impressive that it got as close as it did; what worries me is how authoritatively it presented its buggy code. People are going to trust these systems, even if they shouldn’t, and since it’s likely to be used by people who aren’t experts, errors like those described above aren’t likely to be easily caught. I’m sure the quality will improve in time – these are the early days – but where is this all leading? The bot was so confident in its assertion that C is a dynamically-typed language the other day that it made me doubt myself after decades of C at the center of my brain’s programming-language orientation. I hadn’t studied it formally in school; had I been wrong about it all along?
Interestingly, the python code the bot produced for the sieve was just fine (I just changed the limit for output comparison):
# MAX_PRIMES = 100000 # maximum number of prime numbers to find
MAX_PRIMES = 100 # maximum number of prime numbers to find
# Sieve of Eratosthenes
# Finds all prime numbers up to MAX_PRIMES using the Sieve of Eratosthenes algorithm
def sieve_of_eratosthenes():
primes = [True] * MAX_PRIMES # list to store prime numbers
# 1 is not a prime number
primes[1] = False
# sieve algorithm
for i in range(2, int(MAX_PRIMES ** 0.5) + 1):
if primes[i]:
for j in range(i ** 2, MAX_PRIMES, i):
primes[j] = False
# print the prime numbers
for i in range(1, MAX_PRIMES):
if primes[i]:
print(i)
sieve_of_eratosthenes()2
3
5
7
11
13
17
19
23
29
31
37
41
43
47
53
59
61
67
71
73
79
83
89
97Exciting times. This technology is amazingly promising, and it’s going to change the world. But the flaws are as dangerous as the strengths are thrilling. Here we go.
Reuse
Citation
BibTeX citation:
@online{linberg2022,
author = {Steve Linberg},
title = {ChatGPT Fail: {Sieve} of {Eratosthenes}},
date = {2022-12-06},
url = {https://slinberg.net/posts/2022-12-06-chatgpt-sieve},
langid = {en}
}
For attribution, please cite this work as:
Steve Linberg. 2022. “ChatGPT Fail: Sieve of Eratosthenes.”
December 6, 2022. https://slinberg.net/posts/2022-12-06-chatgpt-sieve.